Machine Learning-based Type Auto-completion for Python – The Blog of Amir Mir
mirblog.net
10 ideas
·169 reads
2

Learn more about artificialintelligence with this collection
Understanding machine learning models
Improving data analysis and decision-making
How Google uses logic in machine learning
Development and Release of Type4Py: Machine Learning-based Type Auto-completion for Python
Dynamic programming languages like Python and TypeScript allows developers to optionally define type annotations and benefit from the advantages of static typing such as better code completion, early bug detection.
However, retrofitting types is a cumbersome and error-prone process. To address this, we propose Type4Py , an ML-based type auto-completion for Python. It assists developers to gradually add type annotations to their codebases. In the following, I describe Type4Py’s pipeline, model, deployments, and the development of its VSCode extension and more.
4
47 reads
Overview
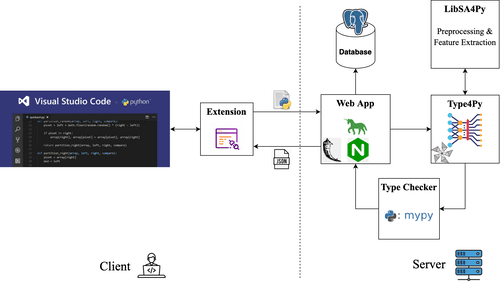
Before going into the detail of the Type4Py’s model and its implementation, it would be helpful to see the overview of Type4Py. In general, there is a VSCode extension at the client-side (developers) and the Type4Py model and its pipeline are deployed on our servers. Simply, the extension sends a Python file to the server and a JSON response containing type predictions for the given file is returned. In the following subsection, I describe each component.
4
28 reads
Dataset
For an ML model to learn and generalize, there is a need for a large and high-quality dataset. Therefore, we created the ManyTypes4Py dataset which contains 5.2K Python projects and 4.2M type annotations. To avoid data leakage from the training set to the test set, we used our CD4Py tool to perform code de-duplication in the dataset. To know more about how we created the dataset, check out its paper .
4
25 reads
Feature Extraction
As with most ML tasks, we need to find a set of relevant features in order to predict type annotations. Here, we consider features as type hints. Specifically, we extract three kinds of type hints, namely, identifiers, code context, and visible type hints (VTHs).
To learn from the extracted sequences, first, we apply common NL pre-processing techniques tokenization (by snake case ), stop word removal and lemmatization. Then, we employ the famous Word2Vec model to generate word embeddings of the extracted sequences in order to train the Type4Py model, which is described next.
4
14 reads
Model Architecture & Training
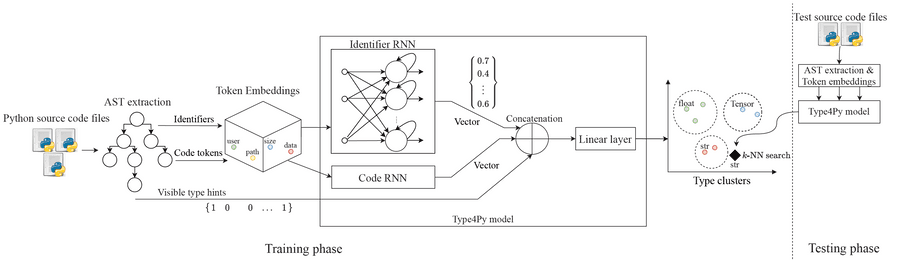
The basic idea is that two RNN captures different aspects of input sequences from both identifiers and code context.
Next, the output of two RNNs is concatenated into a single vector, which is passed through a fully-connected linear layer.
The final linear layer maps the learned type annotation into a high-dimensional feature space, called Type Clusters. In order to create Type Clusters, we need to formulate the type prediction task as a similarity learning problem, rather than a classification problem.
4
12 reads
Implementation
To extract type hints, we first extract Abstract Syntax Trees (ASTs) and perform light-weight static analysis using our LibSA4Py package. NLP tasks are applied using NLTK. To train the Word2Vec model, we use the gensim package.
For the Type4Py model, we use bidirectional LSTMs in PyTorch to implement the two RNNs. To avoid overfitting, we apply the Dropout regularization to the input sequences. To minimize the value of the Triplet loss function, we employ the Adam optimizer. Also, to speed up the training process, we use the data parallelism feature of PyTorch. For fast KNN search, we use Annoy
4
7 reads
Deployment
To deploy the Type4Py model for the production environment, we convert the pre-trained PyTorch model to an ONNX model which allows us to query the model on both GPUs and CPUs with very fast inference speed and lower VRAM consumption. Thanks to Annoy, Type Clusters are memory-mapped into RAM from disk, which consumes less memory.
To handle concurrent type prediction requests from users, we employ Gunicorn ‘s HTTP server with Nginx as a proxy. This allows us to have quite a number of asynchronous workers that have an instance of Type4Py’s ONNX model plus Type Clusters each.
4
5 reads
VSCode Extension
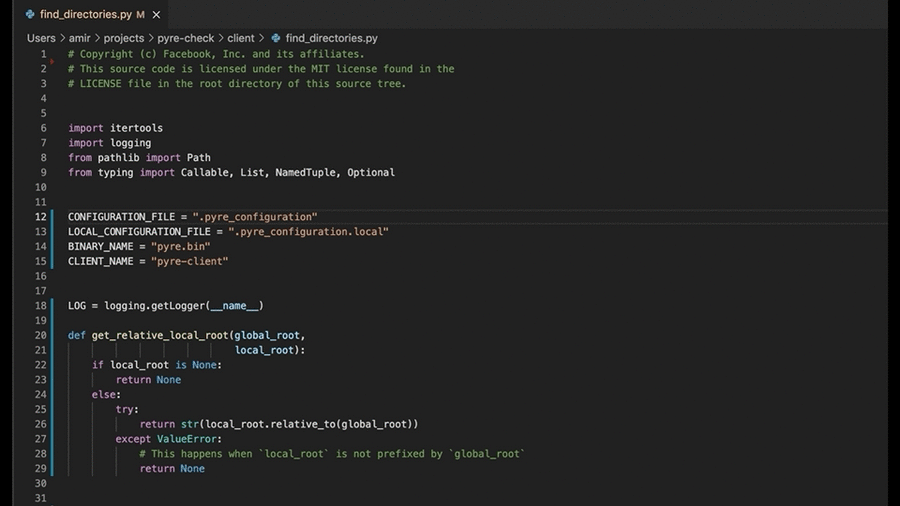
The Type4Py’s VSCode extension is small and simple.
Type slots are functions parameters, return types, and variables, which are located based on the line and column numbers. Currently, type prediction can be triggered via Command Pallete or by enabling the AutoInfer setting, which predicts types whenever a Python source file is opened or selected. Finally, the extension gathers telemetry data from users based on their consent. The Type4Py’s VSCode extension can be installed from the VS Marketplace here .
4
14 reads
Releasing
We have two different environments for development and production as it is common in software development. In the development env., we test, debug, and profile Type4Py’s server-side components before releasing new features/fixes into the production code.
Also, whenever we train a new Type4Py neural model, we test it against its evaluation metrics (see its paper ) and run integration tests to ensure that it produces expected predctions for given Python source files. Finally, the VSCode extension uses the development env. when testing new featues/fixes before releasing a new extension version.
4
6 reads
Roadmap
So far, I have described the current state of Type4Py. For future work, here is our roadmap:
- Enabling the type-checking process for the Type4Py’s predictions using mypy , preferably at the client-side.
- Releasing a local version of the Type4Py model and its pipeline that can be queried on users’ machines.
- Fine-tuning the (pre-trained) Type4Py model on users’ projects to learn project-specific types.
- Releasing a plugin for JetBrains PyCharm and a GitHub action or bot for adding type annotations to Python projects
4
11 reads
CURATED BY





More like this

4 ideas
An introduction to Python Type Hints
peps.python.org

4 ideas
What You Should Know About Data Annotation
becominghuman.ai

15 ideas
Machine learning workflow | AI Platform | Google Cloud
cloud.google.com
Read & Learn
20x Faster
without
deepstash
with
deepstash
with
deepstash
Access to 200,000+ ideas
—
Access to the mobile app
—
Unlimited idea saving & library
—
—
Unlimited history
—
—
Unlimited listening to ideas
—
—
Downloading & offline access
—
—
Personalized recommendations
—
—
Supercharge your mind with one idea per day
Enter your email and spend 1 minute every day to learn something new.
I agree to receive email updates