Development and Release of Type4Py: Machine Learning-based Type Auto-completion for Python
Dynamic programming languages like Python and TypeScript allows developers to optionally define type annotations and benefit from the advantages of static typing such as better code completion, early bug detection.
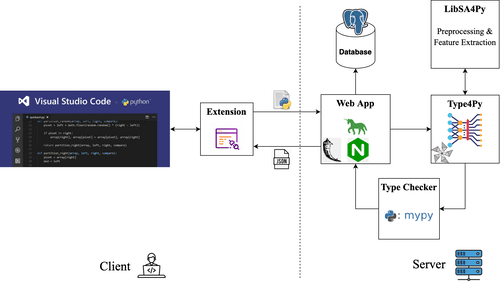
However, retrofitting types is a cumbersome and error-prone process. To address this, we propose Type4Py , an ML-based type auto-completion for Python. It assists developers to gradually add type annotations to their codebases. In the following, I describe Type4Py’s pipeline, model, deployments, and the development of its VSCode extension and more.
4
56 reads

The idea is part of this collection:

Learn more about artificialintelligence with this collection
Understanding machine learning models
Improving data analysis and decision-making
How Google uses logic in machine learning
Related collections




Read & Learn
20x Faster
without
deepstash
with
deepstash
with
deepstash
Personalized microlearning
—
100+ Learning Journeys
—
Access to 200,000+ ideas
—
Access to the mobile app
—
Unlimited idea saving
—
—
Unlimited history
—
—
Unlimited listening to ideas
—
—
Downloading & offline access
—
—
Supercharge your mind with one idea per day
Enter your email and spend 1 minute every day to learn something new.
I agree to receive email updates