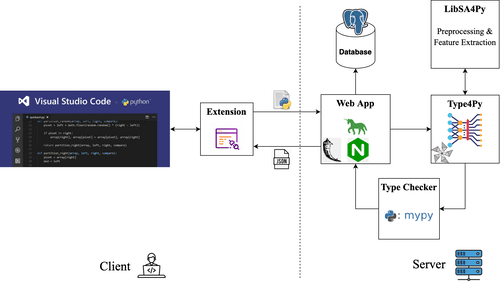
Feature Extraction
As with most ML tasks, we need to find a set of relevant features in order to predict type annotations. Here, we consider features as type hints. Specifically, we extract three kinds of type hints, namely, identifiers, code context, and visible type hints (VTHs).
To learn from the extracted sequences, first, we apply common NL pre-processing techniques tokenization (by snake case ), stop word removal and lemmatization. Then, we employ the famous Word2Vec model to generate word embeddings of the extracted sequences in order to train the Type4Py model, which is described next.
4
20 reads

The idea is part of this collection:

Learn more about artificialintelligence with this collection
Understanding machine learning models
Improving data analysis and decision-making
How Google uses logic in machine learning
Related collections




Read & Learn
20x Faster
without
deepstash
with
deepstash
with
deepstash
Personalized microlearning
—
100+ Learning Journeys
—
Access to 200,000+ ideas
—
Access to the mobile app
—
Unlimited idea saving
—
—
Unlimited history
—
—
Unlimited listening to ideas
—
—
Downloading & offline access
—
—
Supercharge your mind with one idea per day
Enter your email and spend 1 minute every day to learn something new.
I agree to receive email updates