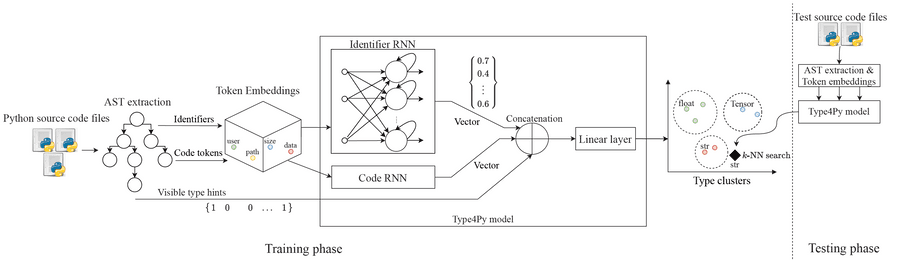
Model Architecture & Training
The basic idea is that two RNN captures different aspects of input sequences from both identifiers and code context.
Next, the output of two RNNs is concatenated into a single vector, which is passed through a fully-connected linear layer.
The final linear layer maps the learned type annotation into a high-dimensional feature space, called Type Clusters. In order to create Type Clusters, we need to formulate the type prediction task as a similarity learning problem, rather than a classification problem.
4
17 reads

The idea is part of this collection:

Learn more about artificialintelligence with this collection
Understanding machine learning models
Improving data analysis and decision-making
How Google uses logic in machine learning
Related collections




Read & Learn
20x Faster
without
deepstash
with
deepstash
with
deepstash
Personalized microlearning
—
100+ Learning Journeys
—
Access to 200,000+ ideas
—
Access to the mobile app
—
Unlimited idea saving
—
—
Unlimited history
—
—
Unlimited listening to ideas
—
—
Downloading & offline access
—
—
Supercharge your mind with one idea per day
Enter your email and spend 1 minute every day to learn something new.
I agree to receive email updates