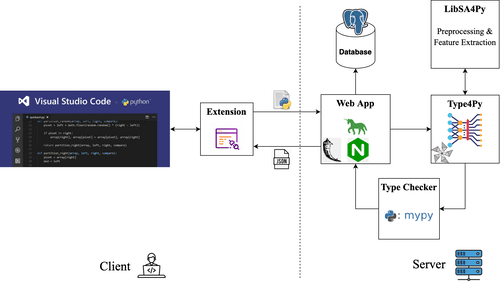
Deployment
To deploy the Type4Py model for the production environment, we convert the pre-trained PyTorch model to an ONNX model which allows us to query the model on both GPUs and CPUs with very fast inference speed and lower VRAM consumption. Thanks to Annoy, Type Clusters are memory-mapped into RAM from disk, which consumes less memory.
To handle concurrent type prediction requests from users, we employ Gunicorn ‘s HTTP server with Nginx as a proxy. This allows us to have quite a number of asynchronous workers that have an instance of Type4Py’s ONNX model plus Type Clusters each.
4
9 reads

The idea is part of this collection:

Learn more about artificialintelligence with this collection
Understanding machine learning models
Improving data analysis and decision-making
How Google uses logic in machine learning
Related collections




Read & Learn
20x Faster
without
deepstash
with
deepstash
with
deepstash
Personalized microlearning
—
100+ Learning Journeys
—
Access to 200,000+ ideas
—
Access to the mobile app
—
Unlimited idea saving
—
—
Unlimited history
—
—
Unlimited listening to ideas
—
—
Downloading & offline access
—
—
Supercharge your mind with one idea per day
Enter your email and spend 1 minute every day to learn something new.
I agree to receive email updates