Releasing
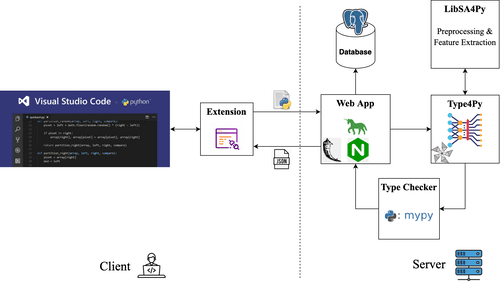
We have two different environments for development and production as it is common in software development. In the development env., we test, debug, and profile Type4Py’s server-side components before releasing new features/fixes into the production code.
Also, whenever we train a new Type4Py neural model, we test it against its evaluation metrics (see its paper ) and run integration tests to ensure that it produces expected predctions for given Python source files. Finally, the VSCode extension uses the development env. when testing new featues/fixes before releasing a new extension version.
4
11 reads

The idea is part of this collection:

Learn more about artificialintelligence with this collection
Understanding machine learning models
Improving data analysis and decision-making
How Google uses logic in machine learning
Related collections




Read & Learn
20x Faster
without
deepstash
with
deepstash
with
deepstash
Personalized microlearning
—
100+ Learning Journeys
—
Access to 200,000+ ideas
—
Access to the mobile app
—
Unlimited idea saving
—
—
Unlimited history
—
—
Unlimited listening to ideas
—
—
Downloading & offline access
—
—
Supercharge your mind with one idea per day
Enter your email and spend 1 minute every day to learn something new.
I agree to receive email updates