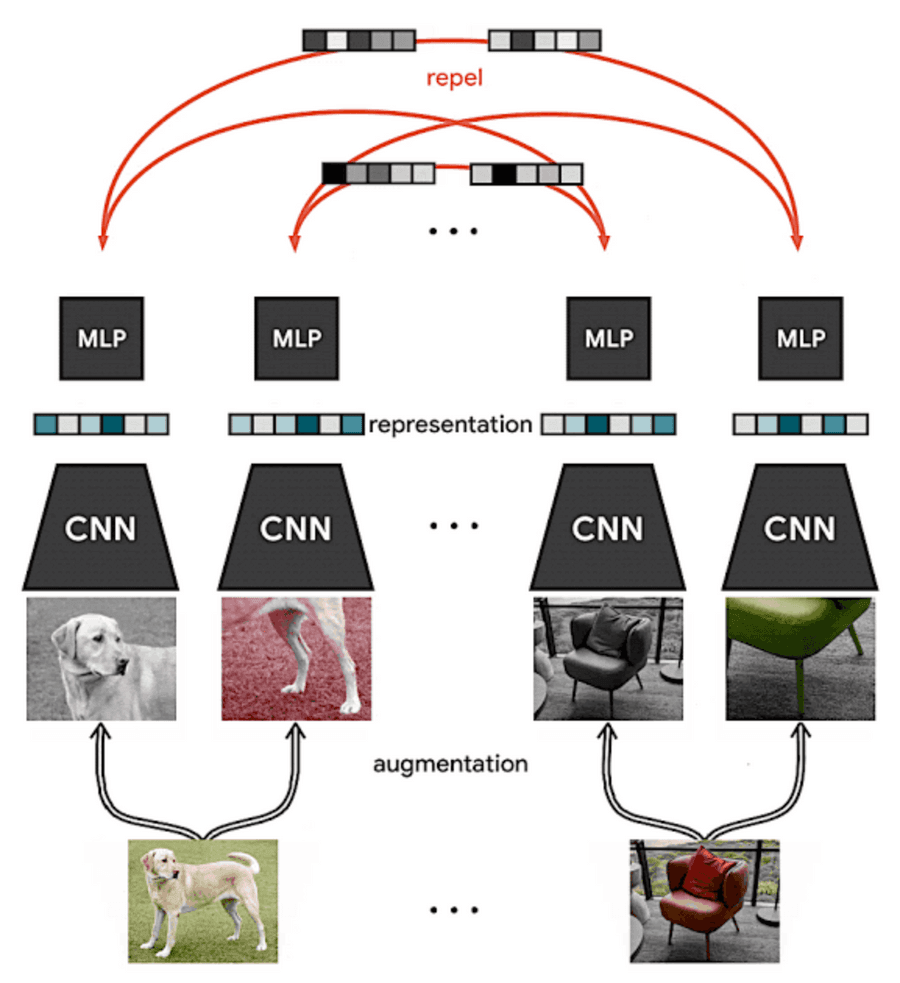
Self-Supervised Learning
Labelled data is expensive, which makes benefiting from the current success in supervised learning unfeasible for smaller companies.
However, good representations can be learned without any task-specific information from raw data.
In self-supervised learning, labels are generated artificially. A common approach is to take multiple augmented views from the same source and contrast them to different sources.
Many papers have proven that simply increasing the similarity (decreasing the distance in the embedding space) of such views from the same source can lead to strong representations.
7
66 reads


The idea is part of this collection:
Learn more about artificialintelligence with this collection
The historical significance of urban centers
The impact of cultural and technological advances
The role of urban centers in shaping society
Related collections




Read & Learn
20x Faster
without
deepstash
with
deepstash
with
deepstash
Personalized microlearning
—
100+ Learning Journeys
—
Access to 200,000+ ideas
—
Access to the mobile app
—
Unlimited idea saving
—
—
Unlimited history
—
—
Unlimited listening to ideas
—
—
Downloading & offline access
—
—
Supercharge your mind with one idea per day
Enter your email and spend 1 minute every day to learn something new.
I agree to receive email updates