Dimensionality Reduction
The process of reduction in the number of dimensions (or feature variables) in datasets is known as Dimensionality Reduction.
If a cube has 1000 points, we can reduce its dimensionality by simply taking the 3D data and viewing it as a 2D model. We can also remove feature variables to reduce the data volume. This is generally done with features that have a low correlation with the dataset and is called feature pruning.
123
381 reads


The idea is part of this collection:

Learn more about problemsolving with this collection
How to make rational decisions
The role of biases in decision-making
The impact of social norms on decision-making
Related collections




Similar ideas to Dimensionality Reduction
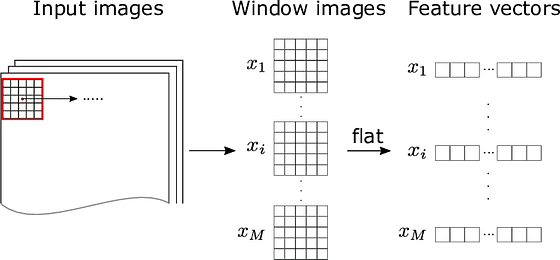
Feature extraction and suitable machine learning model
When dealing with large datasets with many columns and variables, feature extracting is used to divide and reduce existing data into a manageable group.
But for image processing, machines can't extract features such as edges, shapes, or even size in this way
Why we use models
- A model is just a series of calculations that abstractly represent some systems in the real world. We use models all the time.
- We may work out the routes we could take to get to work at a specific time of the day. We use past data to make predictions about what we...
Read & Learn
20x Faster
without
deepstash
with
deepstash
with
deepstash
Personalized microlearning
—
100+ Learning Journeys
—
Access to 200,000+ ideas
—
Access to the mobile app
—
Unlimited idea saving
—
—
Unlimited history
—
—
Unlimited listening to ideas
—
—
Downloading & offline access
—
—
Supercharge your mind with one idea per day
Enter your email and spend 1 minute every day to learn something new.
I agree to receive email updates