
Database indexes
Curated from: en.wikipedia.org
Ideas, facts & insights covering these topics:
7 ideas
·363 reads
8
Explore the World's Best Ideas
Join today and uncover 100+ curated journeys from 50+ topics. Unlock access to our mobile app with extensive features.
What is an index?
A database index is a data structure that improves the speed of data retrieval operations on a database table at the cost of additional writes and storage space to maintain the index data structure. Indexes are used to quickly locate data without having to search every row in a database table every time a database table is accessed.
13
178 reads
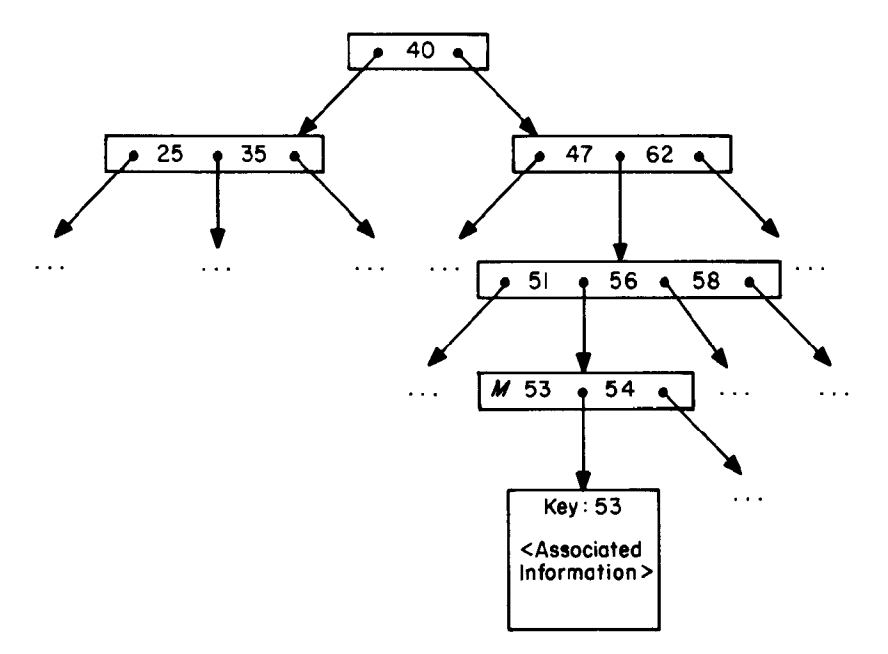
B-Trees
PostgreSQL implements several types of indexes, such as btree, hash, gist, spgist. The default and most common type of index is btree. A btree (balanced tree) allows for easier and faster searching. This can be seen in the image above where we search for the key with the value of 53.
Btrees speed up searches because:
- They sort the values (known as keys) inside of each node.
- They are balanced: B-Trees evenly distribute the keys among the nodes, minimizing the number of times we have to follow a pointer from one node to another.
12
59 reads

What does a PostgreSQL index look like?
When creating an index on the name field(for example), PostgreSQL saves all of them inside a B-Tree - keys are now represented by names. Each entry in the index consists of a C structure called IndexTupleData, and is followed by a bitmap and a value. Bitmaps record if any of the index attributes in a key are NULL, to save space.
Each IndexTupleData structure contains:
- t_tid: This is a pointer to either another index tuple, or to a database record.
- t_info: This contains information about the index tuple, such as how many values it contains, and whether or not there are null values.
11
32 reads
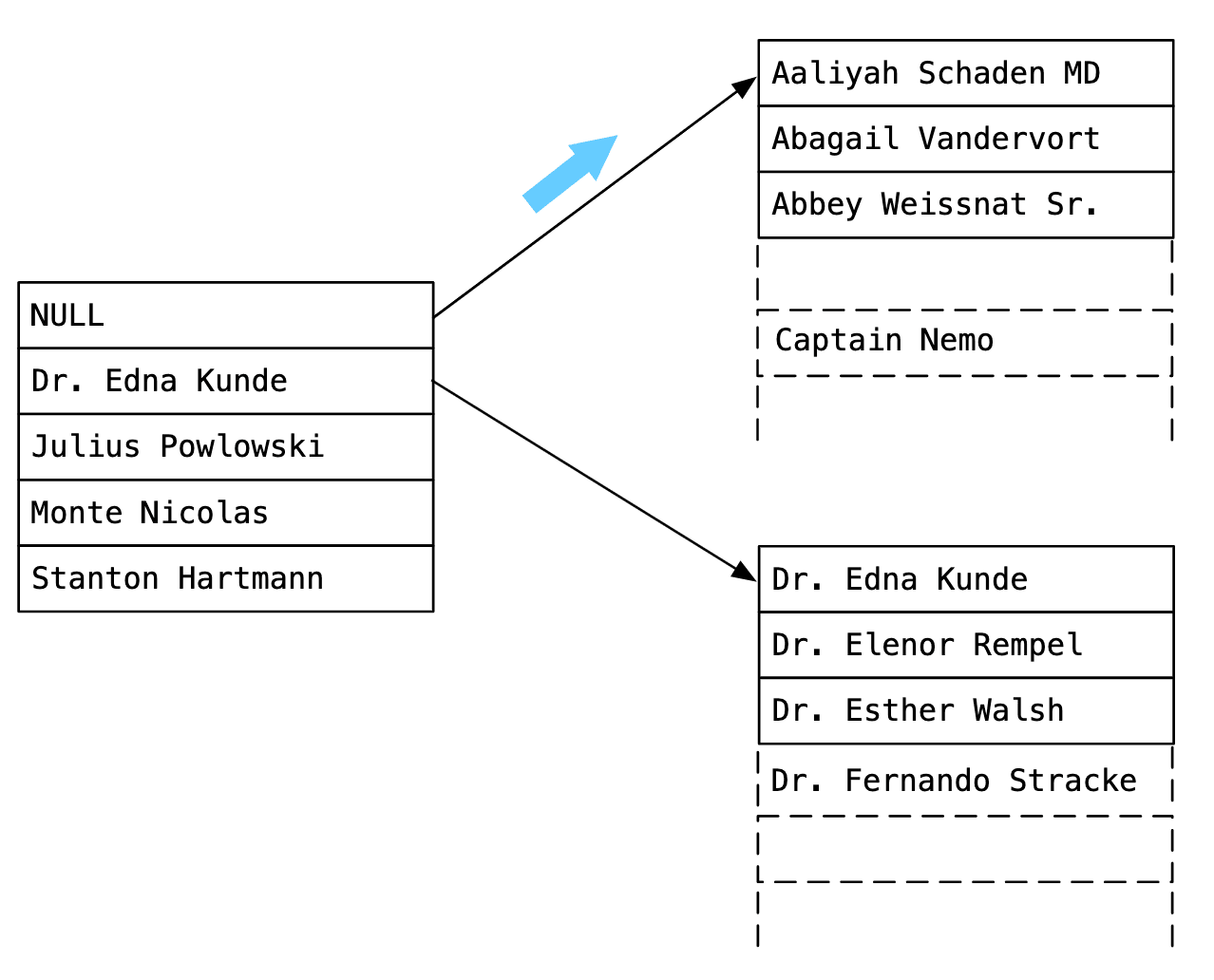
Querying using indexes
Suppose we have an index on names and we query the following: SELECT * FROM users WHERE name = 'Captain Nemo' ORDER BY id ASC LIMIT 1. As you can see in the image, Postgre quickly narrows the results down until it finds the specific node where the name is located. A binary search algorithm is then used to quickly find the desired key in the node. The results are now easily fetched as the index points to the place where 'Captain Nemo' is located in memory.
12
24 reads
Index scans and index-only scans
An example of an index scan is the earlier query. As there is an index on the user column and we asked for all the user details, after the value is found in the index, Postgre then goes to the heap and fetches the other fields.
An index-only scan means that all the needed information is found in the index and there is no need to go to memory. This is useful when querying a pair of fields multiple times - creating an index on those fields will output quicker results.
11
17 reads

Bitmap scans
If you only select a few rows, Postgre will decide on an index scan – if you select a majority of them, Postgre will decide on a table scan. But what if you read too much for an index scan to be efficient but too little for a sequential scan? The solution to the problem is to use a bitmap scan. This way, a single block is only used once during a scan. Postgre will first scan the index and compile those rows / blocks, which are needed at the end of the scan. Then Postgre will take this list and go to the table to really fetch those rows.
11
20 reads
Disadavtanges of indexes
Although indexes are useful as they provide faster searches, having too many of them could turn out to be a problem.
- Space issues: Indexes consume space and if the table the indexes are on are particularly large, it may have an impact.
- Write speed: when inserting, deleting or updating existing rows, not only these values are updates, but also the b-tree, which could prove to be quite slow depending on the table size.
12
33 reads
IDEAS CURATED BY

Similar ideas

1 idea
Foreign Key on Models | Django documentation
docs.djangoproject.com

4 ideas
What is Elasticsearch?
elastic.co

1 idea
Hands-on Tutorial on Python Data Processing Library Pandas – Part 1
datascienceplus.com
Read & Learn
20x Faster
without
deepstash
with
deepstash
with
deepstash
Personalized microlearning
—
100+ Learning Journeys
—
Access to 200,000+ ideas
—
Access to the mobile app
—
Unlimited idea saving
—
—
Unlimited history
—
—
Unlimited listening to ideas
—
—
Downloading & offline access
—
—
Supercharge your mind with one idea per day
Enter your email and spend 1 minute every day to learn something new.
I agree to receive email updates