Explore the World's Best Ideas
Join today and uncover 100+ curated journeys from 50+ topics. Unlock access to our mobile app with extensive features.
Building the Framework - The Challenge
Building a serverless framework certainly has its challenges. One of which is the deployment of cloud infrastructure, which, in the world of serverless, is one of the fundamental operations developers need to do, even while the application is still in development.
Before the version 5 release , Webiny relied on an infrastructure provisioning technology called Serverless Components (not to be confused with Serverless Framework ).
12
101 reads
1. Hard to Customize
While the idea around components for different use-cases certainly sounded interesting, ultimately, it was not ideal for Webiny. We frequently received questions regarding further component configuration and customization, which was not easy to perform.
“How do I configure a different database?”, “How do I set a VPC?”, “How do I set up a specific configuration parameter for my S3 bucket?” were just some of the questions we received.
12
38 reads
2. Using YAML Instead of Code
At Webiny, we believe cloud engineering and infrastructure-as-code is the future, so, naturally, we wanted our users to use familiar code (ideally TypeScript) and development tools to define their cloud infrastructure. Within Serverless Components, the components are configured via YAML files, of which we were never really big fans, simply because of the fact that writing code instead of configurations gives more flexibility to developers.
12
50 reads
3. Vendor Lock-In
Vendor lock-in was introduced at a later stage of the Serverless Components product development. Essentially, to deploy a component, the user is now forced to use a proprietary service that comes with it. And while, among other things, the service enables much faster deployments, from our perspective, we saw this as an additional point of friction for our users. Ideally, users should be able to set up Webiny with only an AWS account.
12
26 reads
Discovering Pulumi
Once we realized Serverless Components wasn’t an ideal solution for Webiny, we started looking for an alternative.
The key features that we were looking for were the following:
- open-source
- use code (preferably TypeScript) to create cloud infrastructure resources
- cloud infrastructure code should be flexible, meaning, users should be able to make adjustments to it
- support for multiple cloud providers is a must
- no vendor lock-in
12
24 reads
- different options when it comes to storing cloud infrastructure state files: a managed SaaS (pulumi.com ) with a console and self-hosted, (for example Amazon S3 )
- ability to deploy cloud infrastructure into multiple environments using its concept of stacks
- great documentation
- a vibrant community of developers and a responsive team behind the product
12
29 reads
Integrating Pulumi with Webiny
For us, the integration of Pulumi with Webiny consisted of three steps:
- figure out how to integrate Pulumi’s programming model with Webiny
- integrate Pulumi CLI into Webiny CLI
- figure out the optimal way of handling cloud infrastructure state files
12
18 reads
Integrating Pulumi’s Programming Model With Webiny
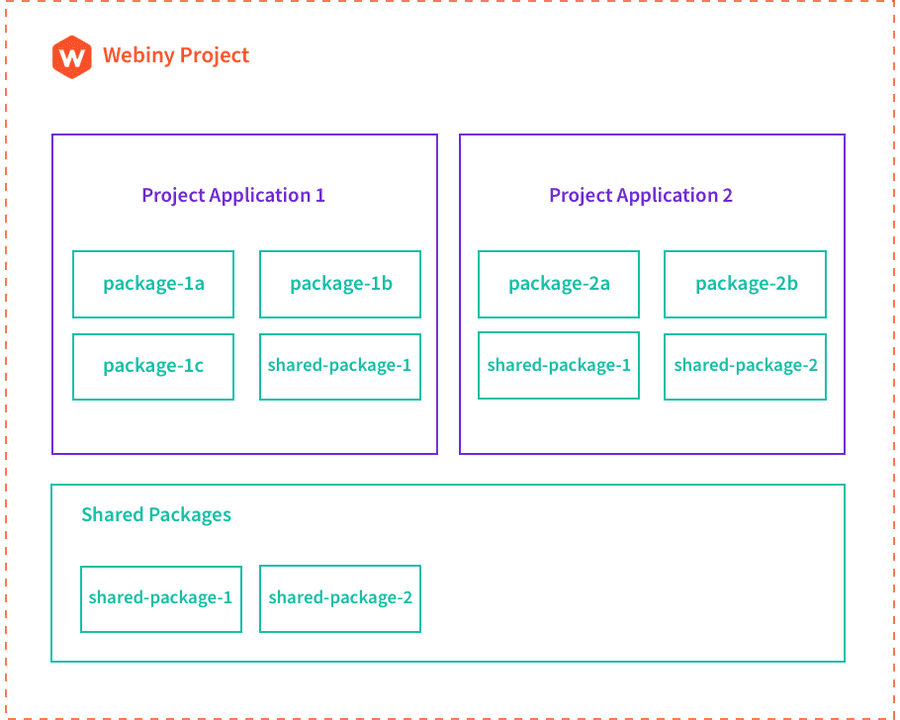
In terms of project organization , every Webiny project consists of two key concepts: packages and project applications (or just applications).
As an example, a default Webiny project includes three project applications:
- API - essentially, represents your GraphQL HTTP API
- Admin Area - the Admin Area (React) application
- Website - the public website, a (React) application with static site generation (SSG) in the cloud
12
17 reads
Pulumi CLI and Webiny CLI
Once we understood how to use Pulumi concepts with Webiny’s project organization, the next step was integrating the Pulumi CLI with the Webiny CLI .
For starters, we didn’t want our users to install the Pulumi CLI manually. We wanted it to happen automatically.
We’ve created our version of the Pulumi SDK , which lets us use the Pulumi CLI more programmatically. all of the necessary Pulumi CLI binaries and plugins are downloaded and stored inside the project’s node_modules folder.
12
14 reads
Cloud Infrastructure State Files
The last piece of the puzzle was storing cloud infrastructure state files. Here we went with the following approach.
For local development, users’ cloud infrastructure state files are stored locally within their Webiny project using the Local Filesystem Backend , which we’ve seen worked great for developers.
On the other hand, for ephemeral environments spawned in CI/CD or long-lived environments like staging or production, through our documentation , we advise our users to use centralized and remote storage by using backends like Amazon S3 and even Pulumi Service (pulumi.com)
12
14 reads
Show Me the Code
As mentioned, by default, every Webiny project comes with three project applications: API, Admin Area, and Website, which are located in the api , apps/admin , and apps/website folders, respectively:
As we can see, every project application follows the same general organization. The two folders in each project are:
- code - contains application code (one or more packages)
- pulumi - contains cloud infrastructure (Pulumi) code
12
16 reads
Furthermore, if we opened each of these pulumi folders, we’d see different cloud infrastructure resources clearly defined via multiple TypeScript classes. As a simple example, if we were to open the apps/admin/pulumi (Admin Area) folder, we’d find the following three files:
- app.ts - deploys an Amazon S3 bucket that hosts the Admin Area (React) application
- cloudfront.ts - deploys an Amazon CloudFront distribution for improved availability
- index.ts - the Pulumi entrypoint file, imports classes defined within separate files
12
14 reads
API Project Application - Different dev and prod Stacks
when it comes to active development, we don’t have to unleash the full potential of the cloud, like we’re doing in staging and production environments.
For example, it probably makes no sense to deploy an Amazon ElasticSearch cluster into multiple availability zones (AZs) in most cases. A single AZ is enough for development purposes.
Another good example are VPCs and potentially NAT Gateways.
What is even more interesting is the fact that this can be achieved with a simple if statement, which we placed in the index.ts.
12
13 reads
Automatic Tagging of Cloud Infrastructure Resources
Another useful feature is the automatic tagging of the deployed cloud infrastructure resources. In other words, every taggable cloud infrastructure resource will be tagged with WbyProjectName and WbyEnvironment tags. For developers, this makes it much easier to see all of the deployed resources within their Webiny project.
We created a tagResources function, which essentially registers a global stack transformation via pulumi.runtime.registerStackTransformation function to achieve this.
12
39 reads
Protect Feature
Finally, to protect our users from accidental deletions of mission-critical cloud infrastructure resources, we’ve used Pulumi’s protect
The protect option marks a resource as protected. A protected resource cannot be deleted directly. Instead, you must first set protect: false and run pulumi up. Then you can delete the resource by removing the line of code or by running pulumi destroy.
The default is to inherit this value from the parent resource and false for resources without a parent.
this feature is automatically enabled for resources like DynamoDB tables , Cognito User Pools and similar.
12
12 reads
IDEAS CURATED BY

Decebal Dobrica's ideas are part of this journey:

Learn more about computerscience with this collection
Understanding machine learning models
Improving data analysis and decision-making
How Google uses logic in machine learning
Related collections




Similar ideas

10 ideas
10 ideas
What is Cloud Computing?
ibm.com
Read & Learn
20x Faster
without
deepstash
with
deepstash
with
deepstash
Personalized microlearning
—
100+ Learning Journeys
—
Access to 200,000+ ideas
—
Access to the mobile app
—
Unlimited idea saving
—
—
Unlimited history
—
—
Unlimited listening to ideas
—
—
Downloading & offline access
—
—
Supercharge your mind with one idea per day
Enter your email and spend 1 minute every day to learn something new.
I agree to receive email updates