Salesforce Open-Sources 'CodeT5', A Machine Learning Model That Understands and Generates Code in Real Time
Curated from: marktechpost.com
Explore the World's Best Ideas
Join today and uncover 100+ curated journeys from 50+ topics. Unlock access to our mobile app with extensive features.
Problem Statement
current coding pre-training systems heavily rely on either an encoder-only model similar to BERT or a decoder-only model like GPT.
Either way, it is suboptimal for generation and understanding tasks.
CodeBERT needs an additional decoder when used for tasks like code summarization. Apart from the above issue, most current methods adopt the conventional NLP pre-training techniques on source code by considering it a sequence of tokens like in natural language.
This largely ignores the rich structural information present in programming languages, which is vital to comprehend its semantics fully.
4
14 reads
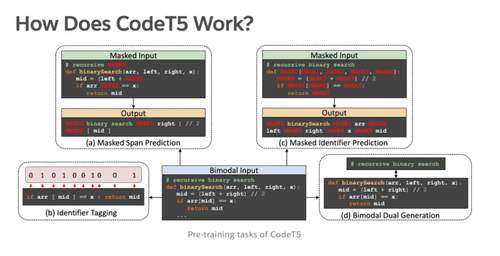
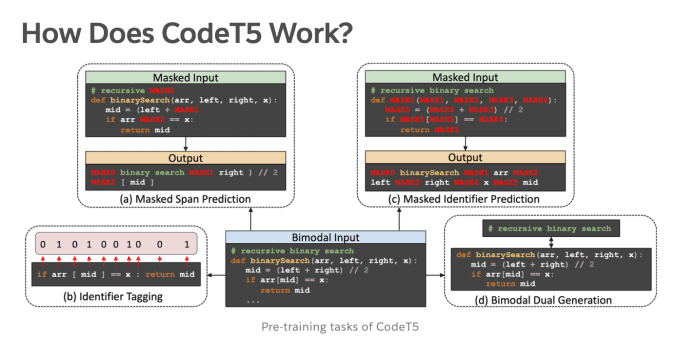
The Salesforce team has created and open-sourced a new identifier-aware unified pre-trained encoder-decoder model called CodeT5 . So far, they have demonstrated state-of-the-art results in multiple code-related downstream tasks such as understanding and generation across various directions, including PL to NL, NL to PL, and from one programming language to another.
CodeT5 is built on a similar architecture to Google’s T5 framework. It reframes text-to-text, where the input and output data are always strings of texts. This allows any task to be applied by this uninformed model.
4
14 reads

The research team of CodeT5 had over 8.35 million examples to train the AI on, including user-written comments from open source GitHub repositories. While training, the largest and most capable version of CodeT5, which had 220 million parameters, took 12 days on a cluster of 16 Nvidia A100 GPUs 40GB memory.
CodeT5 achieves state-of-the-art (SOTA) performance on fourteen subtasks in a code intelligence benchmark CodeXGLUE [3], as shown in the following tables.
4
14 reads
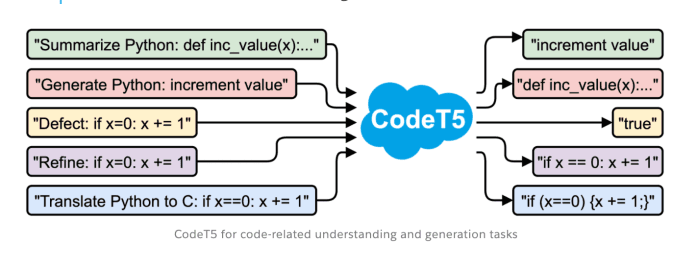
In terms of applications of CodeT5, the Salesforce team plans to use it to build an AI-powered coding assistant for Apex developers. Below you can see an example of a coding assistant with three code intelligence capabilities and powered by CodeT5:
- Text-to-code generation : It can generate code based on the natural language description
- Code autocompletion : It can complete the whole function of code given the target function name
- Code summarization : It can generate the summary of a function in natural language description
4
14 reads
IDEAS CURATED BY

Decebal Dobrica's ideas are part of this journey:

Learn more about artificialintelligence with this collection
Find out the challenges it poses
Learn about the potential impact on society
Understanding the concept of Metaverse
Related collections




Similar ideas

18 ideas
How Search Engines Use Machine Learning: 9 Things We Know For Sure
searchenginejournal.com

1 idea
How To Code Faster in Visual Studio Code
betterprogramming.pub

6 ideas
How to Use Massive AI Models (Like GPT-3) in Your Startup
future.a16z.com
Read & Learn
20x Faster
without
deepstash
with
deepstash
with
deepstash
Personalized microlearning
—
100+ Learning Journeys
—
Access to 200,000+ ideas
—
Access to the mobile app
—
Unlimited idea saving
—
—
Unlimited history
—
—
Unlimited listening to ideas
—
—
Downloading & offline access
—
—
Supercharge your mind with one idea per day
Enter your email and spend 1 minute every day to learn something new.
I agree to receive email updates