
How to Use Massive AI Models (Like GPT-3) in Your Startup
Curated from: future.a16z.com
Ideas, facts & insights covering these topics:
6 ideas
·945 reads
11
Explore the World's Best Ideas
Join today and uncover 100+ curated journeys from 50+ topics. Unlock access to our mobile app with extensive features.
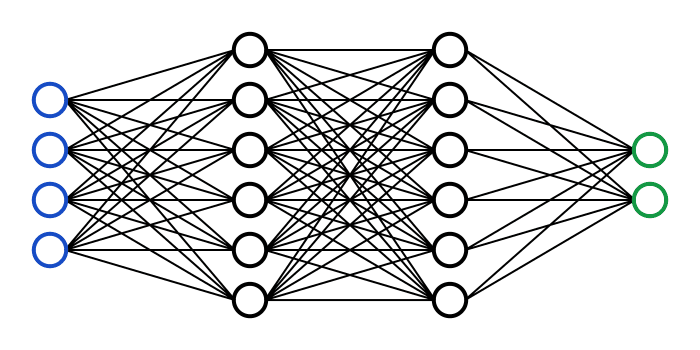
Expensive to train?
Some neural networks are very expensive to train. This led to the popularization of an approach known as pre-training, whereby a neural network is first trained on a large general-purpose dataset using significant amounts of computational resources, and then fine-tuned for the task at hand using a much smaller amount of data and compute resources.
19
264 reads
Pre-trained networks give smaller teams a leg up
The use of pre-trained networks allows a startup, for example, to build a product with much less data and compute resources than would otherwise be needed if starting from scratch. This approach is also becoming popular in academia, where researchers can quickly fine-tune a pre-trained network for a new task, and then publish the results.
20
178 reads

Foundational models
Pre-training has continued to evolve with the emergence of foundation models such as BERT, GPT, DALL-E, CLIP, and others. These models are pre-trained on large general-purpose datasets (often in the order of billions of training examples) and are being released as open source by well-funded AI labs such as the ones at Google, Microsoft, and OpenAI.
They allow startups, researchers, and others to quickly get up to speed on the latest machine learning approaches without having to spend the time and resources needed to train these models from scratch.
19
143 reads
The risks of foundation models: Size & Cost
One of the risks associated with foundation models is their ever-increasing scale. Neural networks such as Google’s T5-11b (open sourced in 2019) already require a cluster of expensive GPUs simply to load and make predictions. Fine-tuning these systems requires even more resources.
More recent models created in 2021-2022 by Google/Microsoft/OpenAI are often so large that these companies are not releasing them as open source – they now require tens of millions of dollars to create and are increasingly viewed as significant IP investments even for these large companies.
19
129 reads
The risks of foundation models: Outsourced innovation
Dataset alignment can also be a challenge for those using foundation models. Pre-training on a large general-purpose dataset is no guarantee that the network will be able to perform a new task on proprietary data. The network may be so lacking in context or biased based on its pre-training, that even fine-tuning may not readily resolve the issue.
Any startup leveraging foundation models in its machine learning efforts should pay close attention to these types of issues.
19
121 reads
The tradeoff
The opportunities and risk around using hosted and pre-trained models has led many companies to leverage cloud APIs in the “experimentation phase” to kickstart product development.
Once a company has determined it has a product-market fit, it often transitions to self-hosted or self-trained models in order to gain more control over data, process, and intellectual property. This transition can be difficult, as the company needs to be able to scale its infrastructure to match the demands of the model, as well as manage the costs associated with data collection, annotation, and storage.
21
110 reads
IDEAS CURATED BY

Liviu Lica's ideas are part of this journey:

Learn more about startup with this collection
How to analyze churn data and make data-driven decisions
The importance of customer feedback
How to improve customer experience
Related collections



Similar ideas
5 ideas
How to Use Massive AI Models (Like GPT-3) in Your Startup
future.a16z.com

4 ideas
What will applied AI look like in 2022?
venturebeat.com
1 idea
Hands-On Transfer Learning with Python
Dipanjan Sarkar
Read & Learn
20x Faster
without
deepstash
with
deepstash
with
deepstash
Personalized microlearning
—
100+ Learning Journeys
—
Access to 200,000+ ideas
—
Access to the mobile app
—
Unlimited idea saving
—
—
Unlimited history
—
—
Unlimited listening to ideas
—
—
Downloading & offline access
—
—
Supercharge your mind with one idea per day
Enter your email and spend 1 minute every day to learn something new.
I agree to receive email updates