
Explore the World's Best Ideas
Join today and uncover 100+ curated journeys from 50+ topics. Unlock access to our mobile app with extensive features.

Where did the word moon come from?
The earth has just one moon. It is best known as the moon in English speaking world because people in ancient times used the moon to measure the passing of the months.
The word moon can be traced to the word mōna, an Old English word from medieval times. Mōna shares its origins with the Latin words metri, which means to measure, and mensis, which means month.
So, we see that the moon is called the moon because it is used to measure the months.
24
342 reads

Galileo's discovery
So, why do the moons arround us have names, while our moon is just the moon?
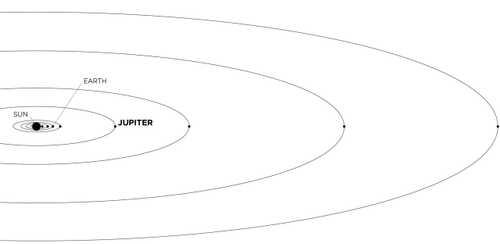
When the moon was named, people only knew about our moon. That all changed in 1610 when an Italian astronomer called Galileo Galilei discovered what we now know are the four largest moons of Jupiter.
Other astronomers across Europe discovered five moons around Saturn during the 1600s. These objects became known as moons because they were close to their planets, just as our own moon is close to the Earth.
It’s fair to say that other moons are named after our own moon.
The newly discovered moons were each given beautiful names to identify them among the growing number of planets and moons astronomers were finding in the solar system.
Many of these names came from Greek myths. The four large moons Galilei discovered around Jupiter were named Io, Europa, Ganymede and Callisto.
21
125 reads
IDEAS CURATED BY

I'm passionate about helping people live their best lives. I'm a lifestyle coach & burnout coach.
Rogier. H's ideas are part of this journey:

Learn more about leadershipandmanagement with this collection
The importance of physical activity
The role of genetics in lifespan
How to maintain a healthy diet
Related collections



Similar ideas


Read & Learn
20x Faster
without
deepstash
with
deepstash
with
deepstash
Personalized microlearning
—
100+ Learning Journeys
—
Access to 200,000+ ideas
—
Access to the mobile app
—
Unlimited idea saving
—
—
Unlimited history
—
—
Unlimited listening to ideas
—
—
Downloading & offline access
—
—
Supercharge your mind with one idea per day
Enter your email and spend 1 minute every day to learn something new.
I agree to receive email updates